本章将会学习到完整的解决机器学习任务的工作流程,建立起可靠的解决深度学习问题的概念框架。
机器学习的四个分支
监督学习
目前最常见,最受关注的深度学习分支。给定一组样本,让机器学习输入到目标的映射。
- 分类
- 回归
- 序列生成
- 语法树检测
- 目标检测
- 图像分割
无监督学习
在没有目标的情况下,让机器寻找输入数据的有趣变换。应用于数据可视化、数据压缩、数据去噪或更好理解数据相关性。通常用于在解决监督学习问题前更好理解数据集。
一些无监督学习方法:dimensionality reduction、clustering。
自监督学习
是监督学习一个特例,标签从输入数据中形成。例如时序监督学习的一个例子:给定视频过去的帧来预测下一帧。
监督学习、无监督学习、自监督学习更像是没用明确界限的连续体。
强化学习
目前主要在研究领域。
评估机器学习模型
核心在于如何衡量generalize(泛化)能力。
验证集
之前很疑惑为什么要专门留出验证集,为什么不直接在测试集上进行验证,这里解决了这个问题。因为虽然没有直接用验证集来进行训练,但是在不断将模型在验证集上的表现作为反馈信号用于调整模型超参数(hyperparameter)的过程中,会有验证集上的信息泄露到模型中。模型在验证集上的表现会越来越好甚至出现过拟合,但我们测试模型性能必须是基于模型在前所未见的数据上的表现,因此验证集和测试集要分开。
分配验证集的常见方式:
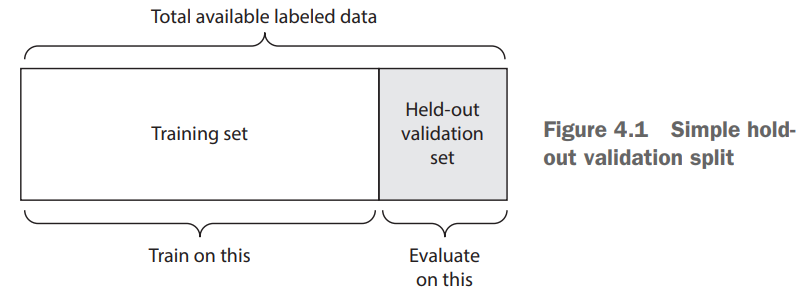
- 留出验证
最简单的验证方式,适用于数据量大的情况。
通常要先打乱数据np.random.shuffle(data)

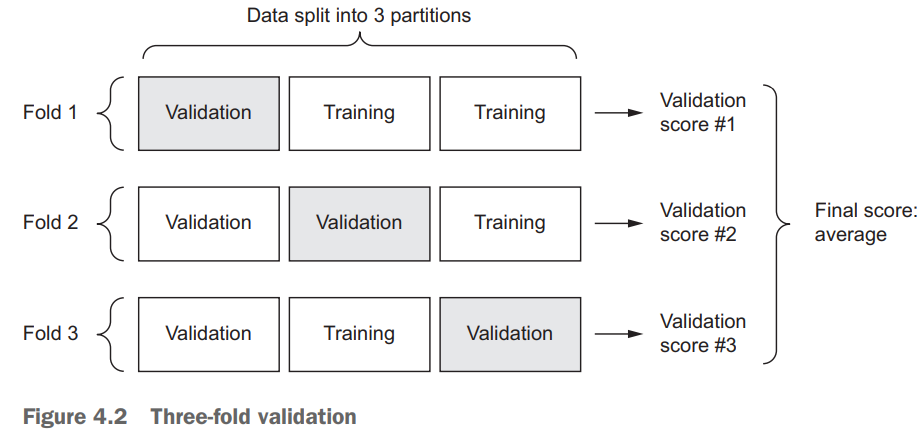
- K折验证
上一章已经提到。适用于可用数据量很小的情况。
- 带有打乱数据的K折验证。
It consists of applying K-fold validation multiple times, shuffling the data every time before splitting it K ways. The final score is the average of the scores obtained at each run of K-fold validation. Note that you end up training and evaluating P × K models (where P is the number of iterations you use), which can very expensive.
一些注意事项:
- 数据代表性:训练集和测试集都要能够代表当前整个数据整体。比如对手写的数字图像进行分类时,如果仅需简单的留出验证,会导致类似训练集上只有0-7,测试集上只有8-9的情况发生,这不能有效验证模型。
- 时间箭头:如果数据是用于预测未来的天气,那就不应该打乱数据,应该始终保证训练数据早于测试数据、
- 数据冗余:要保证训练集和测试集上没有重复的数据点。
总而言之,数据集的分割要看模型的具体应用。
数据处理 特征工程 特征学习
一些准备输入数据和目标的通用基本方法。
数据预处理
- 向量化
所有输入数据必须是浮点数张量(特殊情况下可以是整数张量) - 值标准化
将较大数据和heterogeneous data输入神经网络可能导致梯度更新过大,网络无法收敛。合理的数据输入应该满足以下特性(也可以直接将输入数据转换为标准正态分布)- 取值较小:大部分在0-1范围内
- 同质性:所有特征值取值范围大致相同
- 处理缺失值
将缺失值设置为一个无意义的值,一般设置为0,模型会自动忽略这个值。但如果训练集上数据是完整的,而测试集上存在缺失值,那么模型是无法学会忽略缺失值的。此时需要人为制造一些训练集上的数据缺失,可以将一个样本点复制多次,删除某些特征点。
特征工程
更优雅地解决问题。
making a problem easier by expressing it in a simpler way.

例如,要识别上方钟面的时间。如果直接向神经网络输入图像像素,那需要用到卷积神经网络,虽然神经网络可以自动提取到特征并解决这个问题,但是会耗费大量不必要的算力。更好的解决方案是用python脚本识别出指针所指位置坐标,把坐标交给神经网络。如果再进一步,使用简单的python脚本获得位置坐标对应的指针角度,甚至都不需要机器学习就能解决时间识别问题。
过拟合和欠拟合
The universal tension in machine learning is between optimization and generalization.
迭代一定次数后,模型开始学习仅和数据有关的模式,使得泛化能力降低。最优解决方案是提供更多的训练数据;若无法获得更多数据,则限制模型允许存储的信量,或约束允许存储的信息,强迫模型学习最重要的模式(正则化)。
减小网络大小
即减少可训练参数个数(常被称为模型的容量)。
添加权重正则化
Occam's razor准则适用于机器学习领域,简单模型比复杂模型不容易过拟合。这里的简单模型值参数分布的熵更小(或参数更少)的模型。常见的降低过拟合的方法是让模型权重只能取较小的值,从而限制模型复杂度,让权重分布更加规则。具体实现是在损失函数中添加与较大权重有关的成本。
- L1 regulation:添加的成本与权重系数的绝对值成正比。
- L2 regulation(or weight decay): 添加的成本与权重系数的评分成正比。
由于损失函数只在训练时试用,所以该网络的训练损失会比测试损失大很多。
from keras import regularizers
model = models.Sequential()
model.add(layers.Dense(16, kernel_regularizer=regularizers.l2(0.001),
activation='relu', input_shape=(10000,)))
model.add(layers.Dense(16, kernel_regularizer=regularizers.l2(0.001),
activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))可以同时做两种正则化
from keras import regularizers
regularizers.l1(0.001)
regularizers.l1_l2(l1=0.001, l2=0.001)添加dropout正则化
其原理是通过为上一层的输出添加噪声,来打破不显著的偶然模式,从而降低过拟合。实现方法是随机丢弃上一层输出的某些特征,具体操作是将输出的张量中一定比例(dropout rate,通常设置为0.2-0.5)的值置为0。
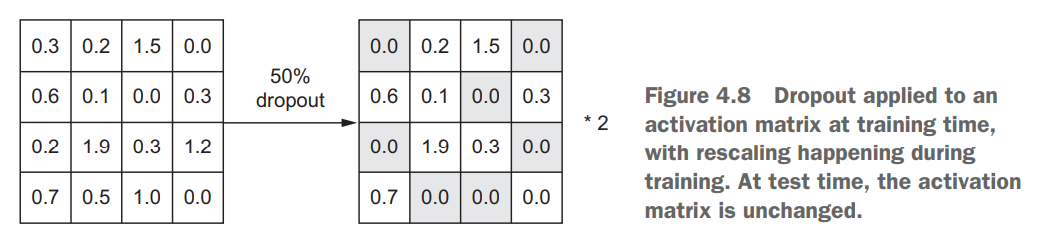
注意图中最右侧有
*2符号,在dropout之后,要将新得到的张量增大droprate倍。
机器学习workflow
定义问题,收集数据
确定输入、输出、问题类型。
两个重要假设:
- 假设输出是可以根据输入进行预测的。
- 假设可用数据包含足够多的信息,足以学习输入和输出之间的关系。
出现问题时,别忘了检验当前状况是否满足这两个假设。
衡量成功的指标
用于确定损失函数。
- 平衡分类问题:ROC AUC
- 排序问题、多标签问题:mean average precision
可在Kaggle了解更多:https://www.kaggle.com/
确定评估方法
- 留出验证集
- K折交叉验证
- 重复K折验证
准备数据
将数据格式化输入神经网络。
优化模型
获得统计功效(statistical power),只要能打败纯随机的基准(dumb baseline),则可以认为获得了统计功效。
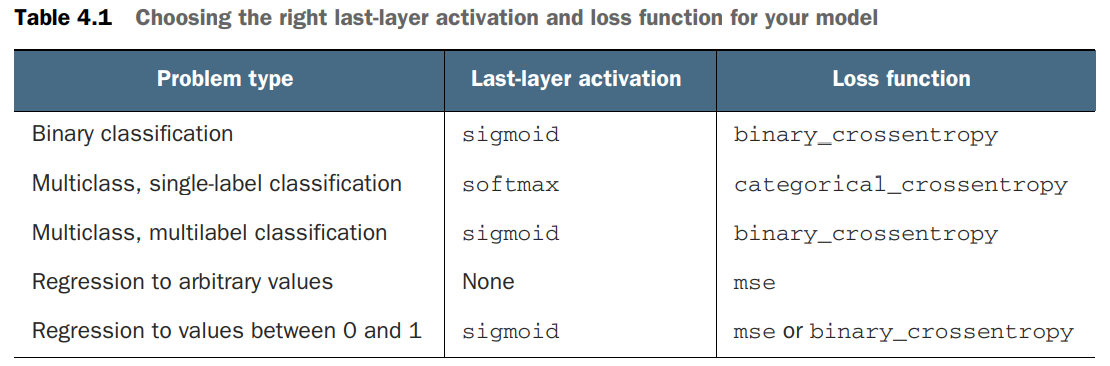
注意最后一层的激活、损失函数、优化配置(优化器、学习率)。
扩大模型规模
最佳模型:刚好在欠拟合和过拟合的边界上,刚好在容量不足和容量过大的边界上。
为了找到这个界限,就需要穿过这个界限,获得一个过拟合的模型。
模型正则化与调节超参数
- 添加drop
- 尝试不同架构:增加或减少层数
- 添加L1/L2正则化
- 尝试不同超参数(每层单元数、优化器学习率)
- 反复做特征工程
之前提到过如果系统性迭代多次,可能会在验证集上过拟合,降低验证过程的可靠性。
Part 1 完结撒花!