
注:若无特殊说明,代码均复制粘贴自Deep Learning with Python官网的Jupyter Notebook文件。
神经网络剖析
层
深度学习的基础组件,将一个或多个输入张量转换为一个或多个输出张量。
大部分层都是有状态的,即有权重。不同的张量格式与不同的数据处理类型要用到不同的层
-
(sample, features)的2D张量通常用密集连接层(densely connected layer),也叫全连接层(fully connected layer,对应Keras的Dense类; -
(samples, timesteps, features)的3D张量通常用循环层(recurrent layer, 比如Keras的LSTM层)来处理; -
储存图像数据的4D张量一般用
二维卷积层(Keras的Conv2D)来处理。
模型
深度学习模型是层构成的有向无环图(和数据结构梦幻联动)。
常见的网络拓扑结构:
- 线性堆叠
- 双分支网络
- 多头网络
- Inception网络
网络的拓扑结构定义了一个假设空间,假设空间内是一系列特定的张量运算。
损失函数与优化器
已经在之前学习过。另外值得注意的是一个具有多个输出的神经网络可能具有多个损失函数,而梯度下降过程必须基于单个标量值,因此在这种情况下,需要对所有损失函数进行取平均数。
另外,选择一个正确的目标函数对于解决问题至关重要,之后的章节会具体提到。
Keras简介
定义模型的两种方法:
- 使用Sequential类,仅用于层的线性堆叠,这是目前最常见的网络架构。
- 使用函数式API(functional API),用于层组成的有向无环图,可以借此构建任意形式的架构。
建立深度学习工作站
-
一定要用N卡!最好买高端显卡,比如泰坦系列!
因为NVIDIA公司在机器学习方面有巨大投入
-
强烈建议使用Unix系统,如果你用Windows,建议你装Ubuntu双系统!
-
建议使用Jupyter Notebook!
Colaboratory
Google推出的免费在线Jupyter notebook。
地址:colab.research.google.com -
可以尝试云实例!
-
后端引擎可选TensorFlow后端、Theano后端、CNTK后端。建议选择TensorFlow。
二分类问题
电影评论分类
使用IMDb数据集。
IMDb数据集介绍:训练集和测试集分别包含25k条褒贬分明的电影评论,其中正面评论和负面评论各占训练集和测试集的50%。
加载数据
将数据加载到内存中(保存到对象里)。
当前的数据结构是,train_data和test_data是由评论组成的列表,每条评论又是单词索引组成的列表。train_label和test_label是0和1组成的列表,0代表negative,1代表positive。
原始数据:

(train_data, train_labels), (test_data, test_labels) = imdb.load_data(num_words=10000)下面这段代码不会用在模型训练当中。它是一段“很有意思”的用于解码评论的代码。
word_index = imdb.get_word_index()
reverse_word_index = dict([(value, key) for (key, value) in word_index.items()]) # 此处语法:[list comprehension](https://stackoverflow.com/questions/34835951/what-does-list-comprehension-mean-how-does-it-work-and-how-can-i-use-it "list comprehension")
decoded_review = ' '.join([reverse_word_index.get(i - 3, '?') for i in train_data[0]])解码后的评论:

可以注意到字符串中存在
?,这应该就是在之前截取前10k个单词时被舍弃的部分。
准备数据
数据只有在被转换为张量后,才能被输入到神经网络中。转换方式有下面两种。
填充列表
填充字符,使每条评论长度相同,然后转化为(samples, word_indices)形状的2D张量。(indice: 索引)
one-hot编码
相关链接:
one-hot编码:https://www.cnblogs.com/shuaishuaidefeizhu/p/11269257.html
enumerate(): https://www.runoob.com/python/python-func-enumerate.html
思路是:创建10k维零向量(因为导入数据时只导入了前10k个常用单词),然后若该向量
import numpy as np
def vectorize_sequences(sequences, dimension=10000):
"""将整数序列编码为二进制矩阵"""
results = np.zeros((len(sequences), dimension)) # 创建形状为len(sequences), dimension的零矩阵
for i, sequence in enumerate(sequences):
results[i, sequence] = 1. # 将result[i]的指定索引设为1
return results
x_train = vectorize_sequences(train_data)
x_test = vectorize_sequences(test_data)理解一下vectorize_sequences()函数:
train_data长这样:

样本向量化之后,长这样
>>> x_train[0]
array([0., 1., 1., ..., 0., 0., 0.])将标签向量化
y_train = np.asarray(train_labels).astype('float32')
y_test = np.asarray(test_labels).astype('float32')https://www.runoob.com/numpy/numpy-array-from-existing-data.html
看起来,系统学习Numpy迫在眉睫……
书上采用了one-hot编码的方式来将数据转换为张量。现在,数据可以被输入神经网络了。
构建网络
我们要依据输入数据的特点,选择合适的网络。
本例中,输入数据是向量,标签是标量,这是最简单的情况。适用于这种情况的一种网络是带有relu激活的Dense层的简单堆叠,如Dense(16, activation='relu')。
对于这种堆叠,需要确定的关键架构是:
- 网络层数
- 网络每层的隐藏单元数
n个隐藏单元对应的权重矩阵w的形状为(input_dimension, 16),与W做点积相当于将数据投影到16维表示空间中。
本例采用的网络架构:
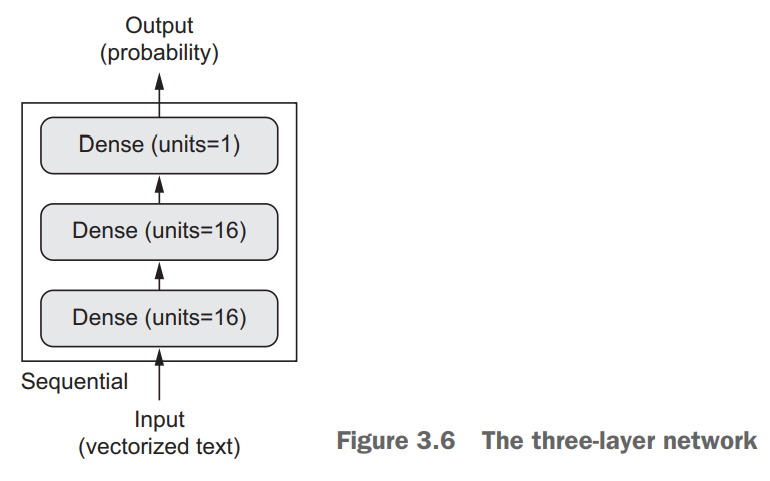
中间层用
relu,最后一层用sigmoid。每个
relu层都实现了output = relu(dot(W, input) + b)
from keras import models
from keras import layers
model = models.Sequential(
layers.Dense(16, activation='relu', input_shape=(10000,)),
layers.Dense(16, activation='relu'),
layers.Dense(1, activation='sigmoid')
)关于激活函数:
这个地方只是大概理解了,之后书上应该会有更详细的介绍。意思大概是说,如果没有激活函数,那么输入输出间就是线性变换(仿射变换),且多个层线性堆叠实现的仍然是线性运算,添加层数对扩展假设空间并无帮助,因此需要通过添加剂或函数来实现这一操作。
选择rmsprop优化器和binary_crossentropy损失函数。
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy'])可以通过传入一个优化器类实例来自定义优化器;可以通过向loss和metrics参数传入函数对象来自定义损失函数或指标函数。
验证模型
将前10k个数据作为验证集,在训练过程中监控模型在前所未见的数据上的精度。这一过程通过将验证数据传入validation_data参数来完成。
# 分割数据
x_val = x_train[:10000]
partial_x_train = x_train[10000:]
y_val = y_train[:10000]
partial_y_train = y_train[10000:]
# 训练模型
history = model.fit(partial_x_train,
partial_y_train,
epochs=20,
batch_size=512,
validation_data=(x_val, y_val))模型训练完毕,返回了一个History对象,该对象有history成员,包含训练过程所有数据,它是一个字典,包含val_acc、acc、val_loss、loss四个条目。
可视化训练损失和验证损失
import matplotlib.pyplot as plt
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(acc) + 1)
# "bo" is for "blue dot"
plt.plot(epochs, loss, 'bo', label='Training loss')
# b is for "solid blue line"
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()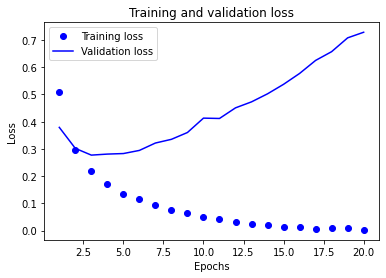
可视化训练精度和验证精度
history_dict = history.history
history_dict.keys()
plt.clf() # clear figure
acc_values = history_dict['accuracy']
val_acc_values = history_dict['val_accuracy']
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()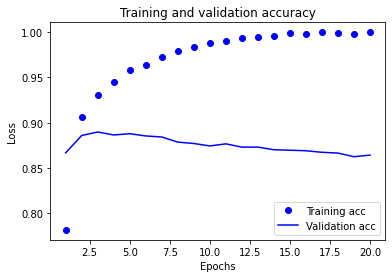
由图可知,大约在第3次训练时,验证精度达到最高,之后出现过拟合现象。
使用模型
可以用model.predict()方法来预测某条评论。
小结
- 数据需要预处理。
- 对于二分类问题,网络的最后一层应该只有一个单元,并使用
sigmoid激活的Dense层。 - 二分类问题的
sigmoid标量输出,应该使用binary_crossentropy损失函数。
一些题外话:我感觉我这“笔记”属实多了点,有点在抄书的感觉了。明天好好思考一下这个问题,还是应该少记一些东西。另外看看能不能把Jupyter Notebook的内容直接嵌入到文章内,这应该是记python笔记的最佳方案。
次日:已经通过笨办法实现了Jupyter Notebook的嵌入。
多分类问题
本节是解决单标签、多分类问题。
使用路透社数据集:由短新闻及其对应主题组成,包括46个互斥的主题,每个主题至少有10个样本。
加载数据集¶
限定只加载前10000个最常出现的单词,看起来它的数据储存方式与IMDb数据集一致,每个样本都是一个整数列表,表示单词索引。
准备数据¶
使用和初始化IMDb数据集一样的方式来初始化。
将标签向量化有两种方法:
- 转换为整形张量。将列表借用Numpy转化为张量,即
y_train = np.array(train_labels) one-hot编码,Keras内置了one-hot编码。
以上两种方法分别应该用不同的损失函数进行处理(数学原理相同,接口不同)。
from keras.utils.np_utils import to_categorical
one_hot_train_labels = to_categorical(train_labels)
one_hot_test_labels = to_categorical(test_labels)
构建网络¶
- 输出类别从2个变成46个,16维的中间层已经不足以区分46个不同的类别了,维度较小的层可能成为
信息瓶颈,导致相关信息永久丢失。因此这次采用64维中间层。 - 但最后一层只有46个维度,表示输出一个46维向量,每个维度表示不同的输出类别。由于要输出概率分布,因此最后一层采用
softmax激活。 - 损失函数是
categorical_crossentropy(分类交叉熵),用于衡量真实分布和网络输出的概率分布间的距离。
from keras import models
from keras import layers
model = models.Sequential()
model.add(layers.Dense(64, activation='relu', input_shape=(10000,)))
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(46, activation='softmax'))
验证模型¶
类似上一节。
回归问题
回归问题是预测一个连续值,而非离散的标签。
本例要预测20世纪70年代中期波士顿房屋价格中位数。
波士顿数据集:输入数据包含犯罪率、地产税等,不同数据有不同取值范围。
from keras.datasets import boston_housing
(train_data, train_targets), (test_data, test_targets) = boston_housing.load_data()
train_data
array([[1.23247e+00, 0.00000e+00, 8.14000e+00, ..., 2.10000e+01,
3.96900e+02, 1.87200e+01],
[2.17700e-02, 8.25000e+01, 2.03000e+00, ..., 1.47000e+01,
3.95380e+02, 3.11000e+00],
[4.89822e+00, 0.00000e+00, 1.81000e+01, ..., 2.02000e+01,
3.75520e+02, 3.26000e+00],
...,
[3.46600e-02, 3.50000e+01, 6.06000e+00, ..., 1.69000e+01,
3.62250e+02, 7.83000e+00],
[2.14918e+00, 0.00000e+00, 1.95800e+01, ..., 1.47000e+01,
2.61950e+02, 1.57900e+01],
[1.43900e-02, 6.00000e+01, 2.93000e+00, ..., 1.56000e+01,
3.76700e+02, 4.38000e+00]])
准备数据¶
由于输入数据取值范围差别大会影响学习效果,因此通过numpy将其全部转化为标准正态分布(期望值$\mu=0$,标准差$\sigma=1$)来将数据标准化。
mean = train_data.mean(axis=0)
train_data -= mean
std = train_data.std(axis=0)
train_data /= std
test_data -= mean
test_data /= std
构建网络¶
训练数据越少,越容易出现过拟合现象,我们通过使用较小的网络来降低过拟合。
- 网络最后一层只有1个单元且无激活函数,因为标量回归只输出单一连续值。
- 损失函数:
mse均方误差 - 监控指标:
MAE平均绝对误差
from keras import models
from keras import layers
def build_model():
# Because we will need to instantiate
# the same model multiple times,
# we use a function to construct it.
model = models.Sequential()
model.add(layers.Dense(64, activation='relu',
input_shape=(train_data.shape[1],)))
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(1))
model.compile(optimizer='rmsprop', loss='mse', metrics=['mae'])
return model
K折验证¶
为了在调节网络参数的同时对网络进行评估,可以将数据划分为训练集和验证集。但由于数据点很少,验证集很小,导致方差波动较大,得到的数据无法可靠反映模型质量。因此可以采用K折交叉验证,操作方式很简单,看图就会。

实现起来很简单,代码如下:
num_epochs = 500
all_mae_histories = []
for i in range(k):
print('processing fold #', i)
# Prepare the validation data: data from partition # k
val_data = train_data[i * num_val_samples: (i + 1) * num_val_samples]
val_targets = train_targets[i * num_val_samples: (i + 1) * num_val_samples]
# Prepare the training data: data from all other partitions
partial_train_data = np.concatenate(
[train_data[:i * num_val_samples],
train_data[(i + 1) * num_val_samples:]],
axis=0)
partial_train_targets = np.concatenate(
[train_targets[:i * num_val_samples],
train_targets[(i + 1) * num_val_samples:]],
axis=0)
# Build the Keras model (already compiled)
model = build_model()
# Train the model (in silent mode, verbose=0)
history = model.fit(partial_train_data, partial_train_targets,
validation_data=(val_data, val_targets),
epochs=num_epochs, batch_size=1, verbose=0)
mae_history = history.history['val_mean_absolute_error']
all_mae_histories.append(mae_history)
完结撒花!
因为完全没有python、numpy、深度学习的任何基础,这一章看起来还是比之前更费力了,要不停查资料才能看懂代码,不过终于搞定之后还是蛮有成就感的!