
链接:初识卷积神经网络
卷积神经网络
举例:一个简单的对MNIST数字进行分类的卷积神经网络。
from keras import layers
from keras import models
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.Flatten())
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(10, activation='softmax'))网络架构概览:

卷积运算
Dense学习到的是全局模式,卷积层学到的是局部模式。在本例中,全局指的就是整张图的所有像素,局部则是图像中的边缘、纹理等,本例中局部大小为$3\times 3$。
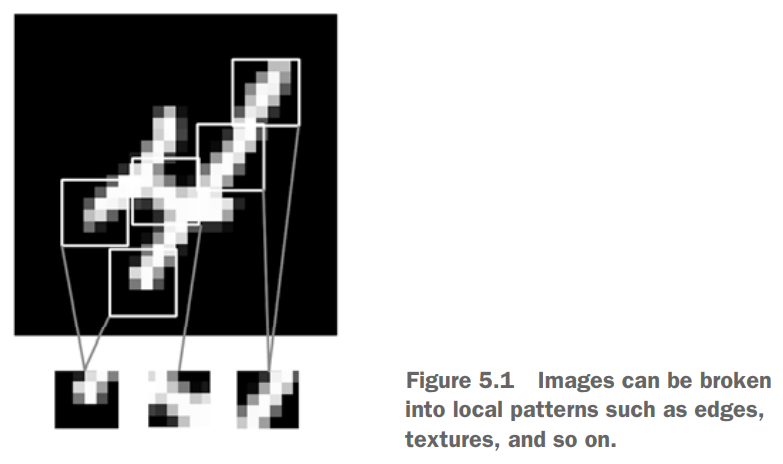
卷积运算特性
- 学习到的模式具有平移不变性(
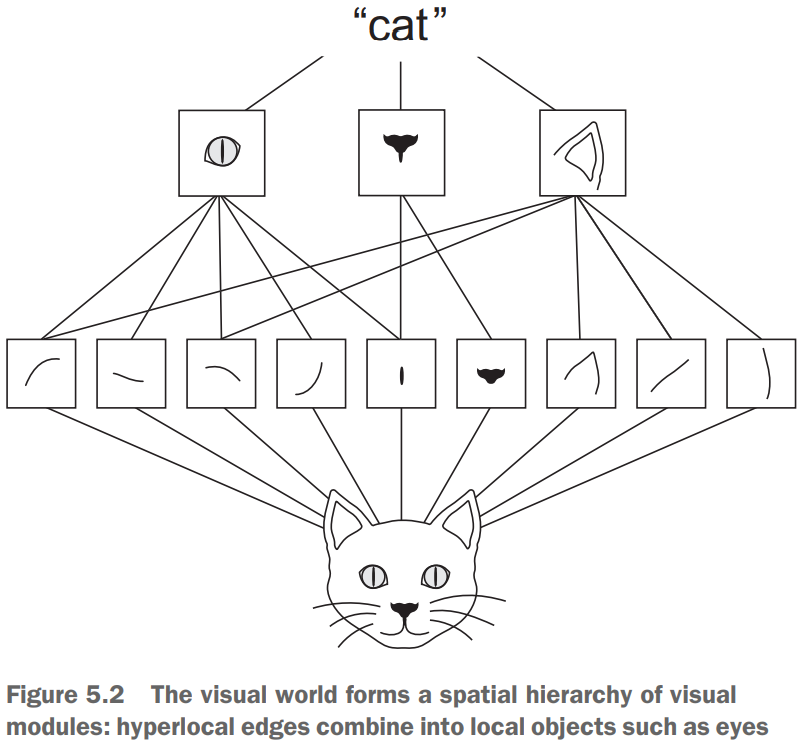
translation invariant)。例如在图片的右下角识别到某个特征后,若此特诊出现在样本的左上角,它依然能够被识别(而Dense层却需要重新学习才能做到)。因为视觉世界从根本上具有平移不变性,用更少的样本就能学到具有泛化能力的数据表示。 - 可以学到模式的空间层次结构。每一层可以由上一层的特征组成更大的模式,使得卷积神经网络可以有效学习越来越复杂、抽象的视觉概念。因为视觉世界从根本上具有空间层次结构。
过滤器对输入数据的某一方面进行编码,如单个过滤器可以从更高层次编码这样一个概念:“输入包含一张脸”。
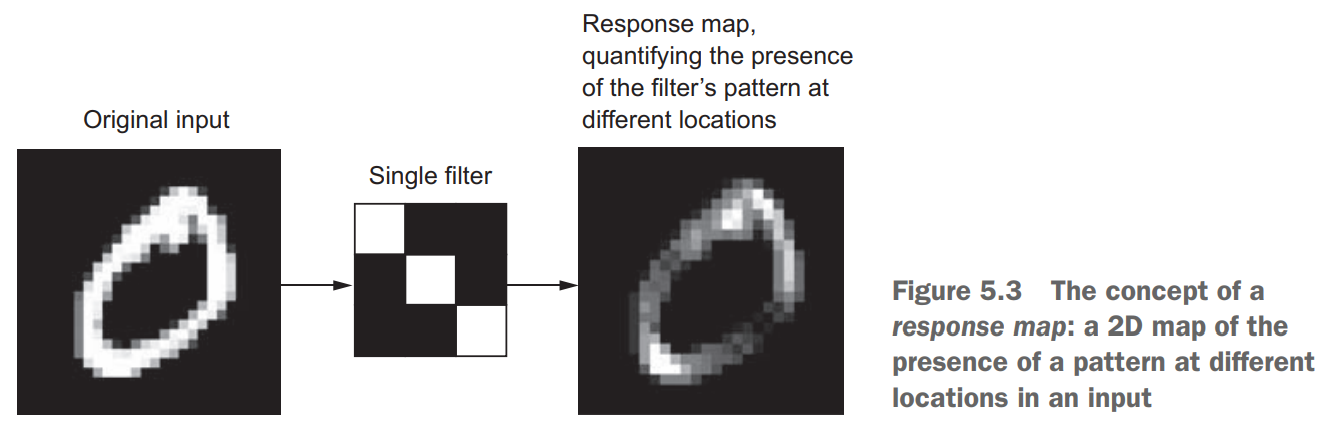
卷积操作输出特征图,输入数据的图片深度轴代表RGB值(或HSL等),而卷积后特征图的深度轴,每一层是图片在某个flitter(一个权重矩阵,称作卷积核)上的响应图。
卷积的关键参数:
- 图块尺寸:常为$3\times 3$或$5\times 5$。
- 特征图深度:卷机所计算的过滤器数量。
Conv2D(output_depth, window_height, window_width)卷积工作原理
某一个卷积核的卷积操作图示:
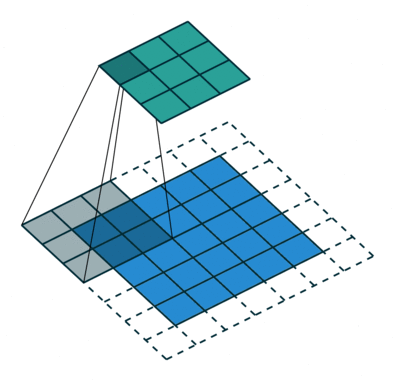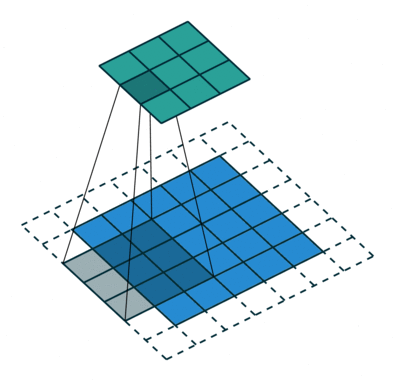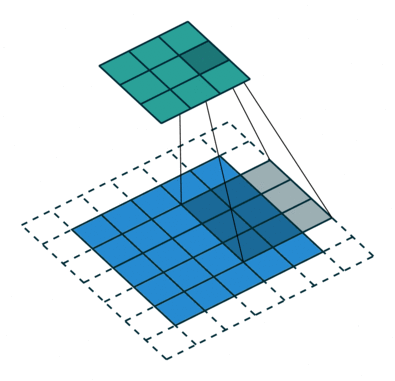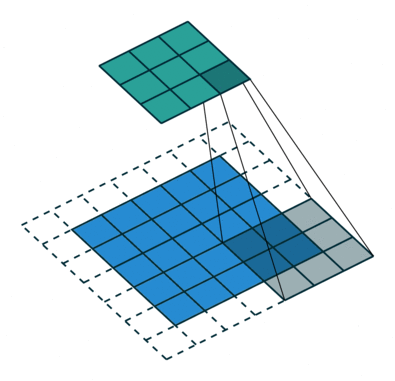
卷积核为3*3,步长为2和填充的2D卷积
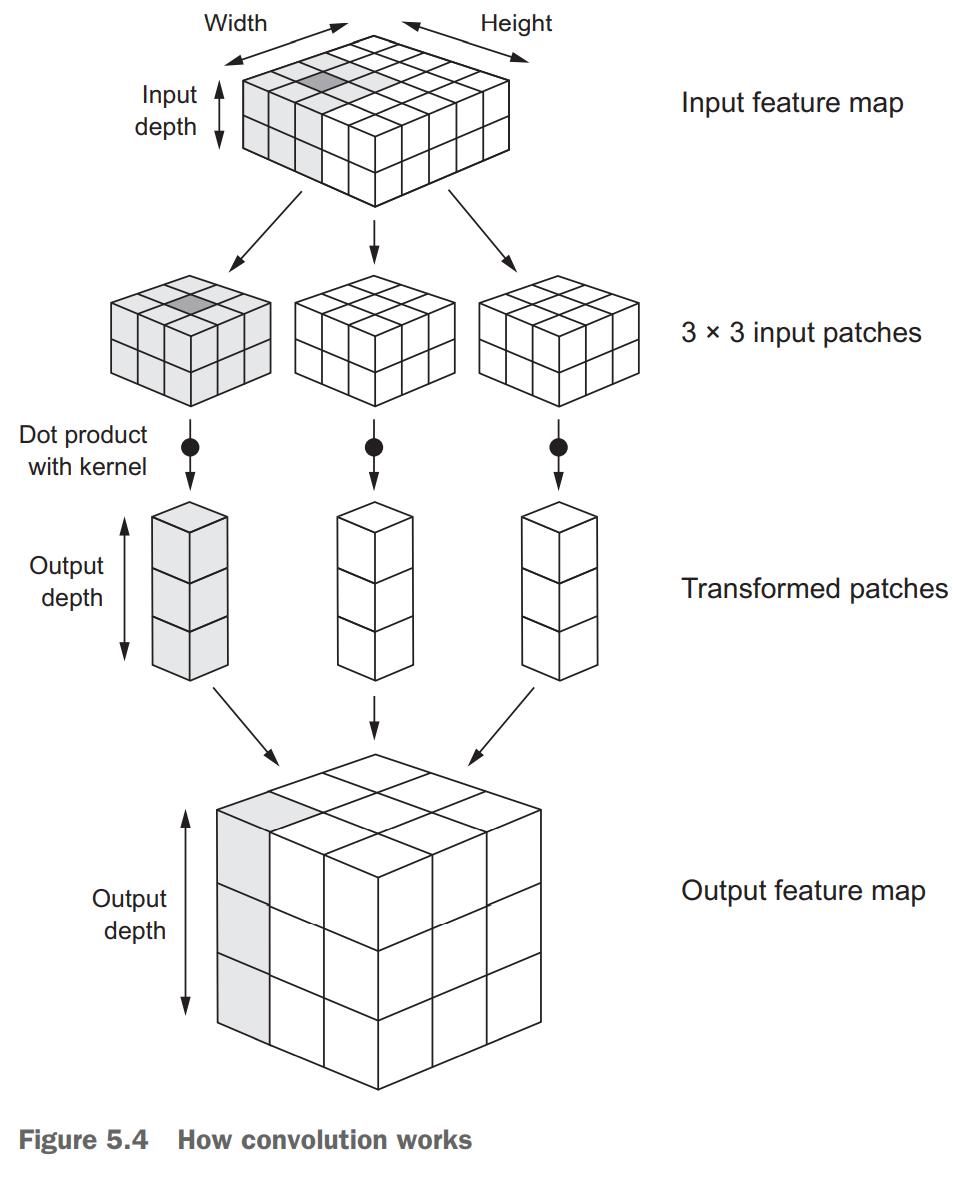
上图中,一个输入被分成9个图块,每个图块与3个卷积核做张量积,按照原来的相对位置再组合在一起,输出特征图。
卷积填充
由于边界效应,卷积会在一个轴上损失2个方块,可以通过设置padding = same参数来填充,保证输入输出高宽一致;若保持默认设置padding = valid则表示不填充。
卷积步幅
见上方的卷积和操作图示。
最大池化运算
最大池化的目的是将更多的信息集中到更小像素范围内,让后续的卷积操作能在更小的算力代价下覆盖更大的信息量。通常采用$2\times 2$,步幅为2的最大池化,替代方案有平均池化、步进卷积等,但效果一般不如最大池化。最合理的方案是先生成密集特征图(通过无步进卷积),然后观察小图块上的最大激活(最大值能比平均值更好反映特征)。
从头训练一个模型
数据增强
ImageDataGenerator
保存模型
`model.save('filename.h5')
预训练模型
Keras内置一些预训练好的模型,如有名的VGG、ResNet-50、MobileNet等。用这些预训练好的模型的卷积层来提取出图像的视觉特征,然后将其用NumPy数组的形式保存下来,再自己用这些数据去训练自己的分类器。这个过程被称为特征提取。
不使用数据增强的快速特征提取
我不是很明白为什么这个方式不能使用数据增强。
使用数据增强的特征提取
扩展conv_base模型,将其冻结后作为模型的一部分参与训练。同时也可以微调模型,将更顶层的卷积块解冻,训练其中的参数。
.
.
.
这篇文章尝试了一下新的排版,CSS样式:
.article-header-style-1 article h1:after {
width: 100%;
height: 13px;
}