基本概念
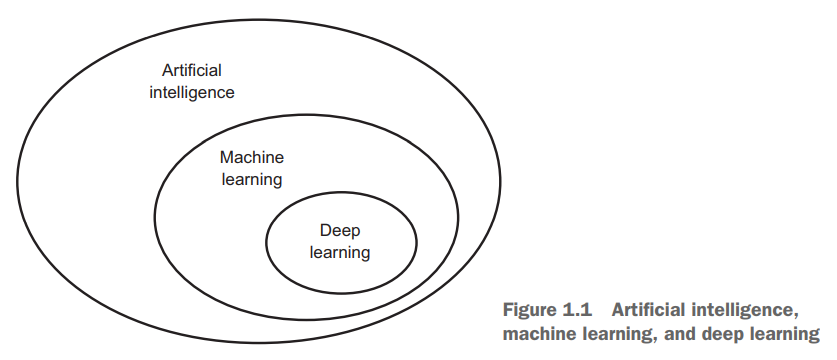
人工智能
曾经符号主义人工智能盛行,但它的能力被局限于解决明确的逻辑问题。更加复杂、模糊的问题,如图像分类、语音识别和语言翻译,由机器学习接任。
表示(Representation)
机器学习三要素
- 输入数据点,如图片
- 预期输出的示例,如图片所对应的正确标签
- 衡量算法效果好坏的方法。这是一种反馈信号,用于调节算法的工作方式。这个调节步骤就是“学习”
机器学习和深度学习的核心问题在于学习输入数据的有用表示,“学习”即寻找更好数据表示的自动搜索过程。
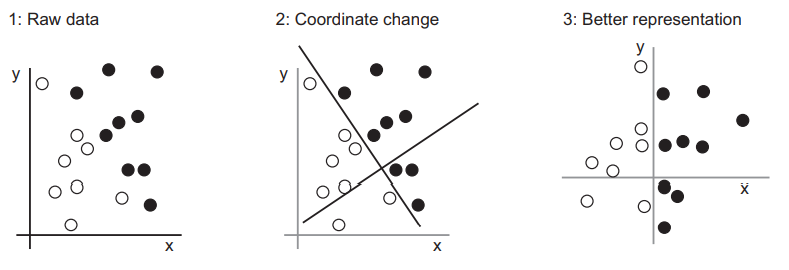
机器学习算法都回去寻找一种能够根据任务将数据转化为更有用表示的变换,而寻找这种变换并不是计算机的创造性活动,而只是遍历一组预先定义好的操作,这组操作被称为“假设空间”。
机器学习
定义:在预先定义好的可能性空间中,利用反馈信号的指引来寻找输入数据的有用表示。
利用机器学习,我们向计算机输入数据,以及预期获得的答案,由计算机输出规则。随后这些规则可用于新的数据,并使计算机自主生成答案。
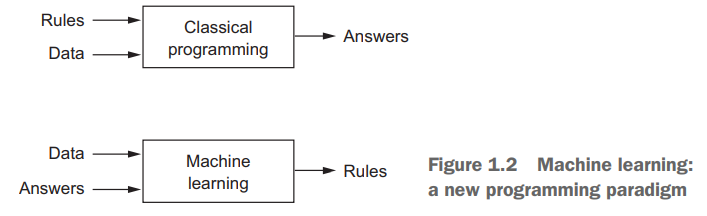
机器学习是训练出来的,而不是明确地用程序编写的。机器寻找示例中的统计结构,但并不依托于经典的统计分析。机器学习(尤其是深度学习)是以工程为导向的,它所运用的数学理论非常少。关于机器学习的想法更多是靠实践证明,而非理论推导。
深度学习
深度学习是机器学习的一个分支领域
技术定义:学习数据表示的多级方法。
从连续的层layer中进行学习,这些层对应越来越有意义的表示。
相关概念
- 深度:数据模型中包含的层数
- 神经网络:用于训练分层的模型
工作原理
神经网络对每个层的操作被保存在该层的权重weight(或称参数parameter)中,其本质是一串数字。即每层实现的变换由其权重来参数化parameterize。
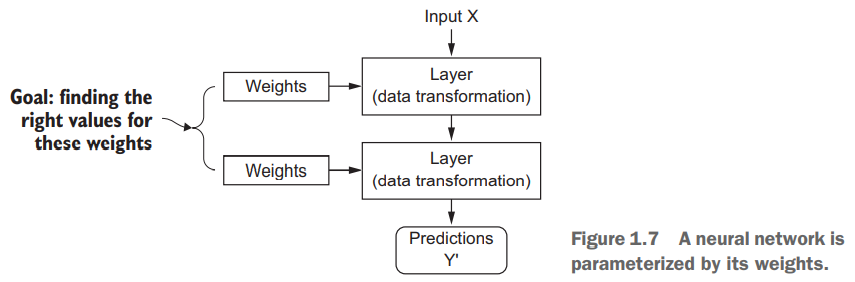
系统先随机对神经网络的权重赋值,对于输出的值,通过
损失函数(loss function)来衡量输出与预期值之间的距离,以此计算效果好坏。然后将该距离值作为反馈信号,由优化器(optimizer)来对权重值进行微调,实现所谓的反向传播(backpropagation)算法。通过循环训练(training loop)来重复上述过程,使得输出值不断逼近预期结果。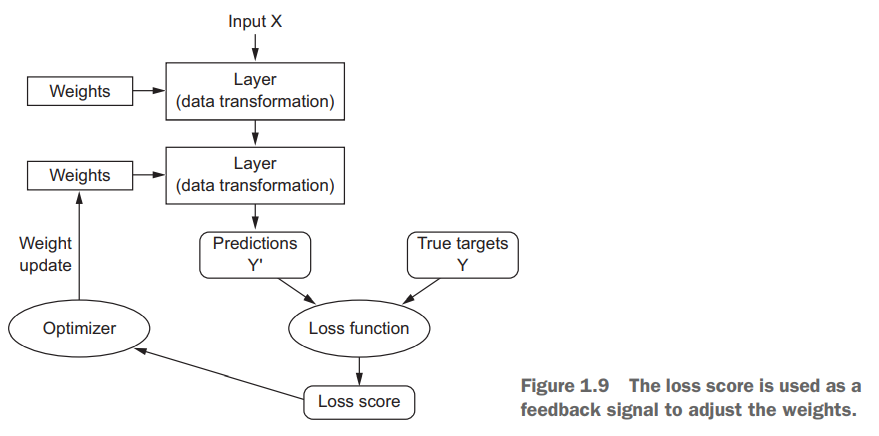
机器学习简史
1 概率建模
最有名的概率建模算法是朴素贝叶斯算法。
另一个密切相关的模型是logistic回归(logistic regression, logreg),是一种分类算法。
2 早期神经网络
20世纪80年代,很多人独立地重新发现了反向传播算法。
贝尔实验室于1989年发明LeNet。
3 核方法
4 决策树、随机森林和梯度提升机
5 现代深度神经网络
off-topics
一些off-topics的有趣名词:
摩尔定律:百度百科